Weeks 3-6, Or the Monster Emerges
Data Monster alpha is just a few days away and now I can come back up for air and look at this first dive into my own wee language. And return to my poor, neglected blog.
Data-What Again?
Much-alluded to, yet little explained in these parts, the Data Monster is a domain specific language that transpiles to d3.js files. Because d3 is so idiomatic and yet so verbose, it seemed an ideal target for a transpiler. The target user is someone who is prototyping a visualization or even building a simple d3 component. Since it generates a plain .js file, Data Monster can also be used just to jumpstart the scaffolding of a chart, with specifics added into the generated file itself.
A lot more details are in the README and CHOMPME.
The Schedule
Because I wanted to have something for people who aren’t me to look at maybe bang on at Open Vis Conf (starting Monday!!), I put together a four-week schedule.
- week 1: planning & grammar
- week 2: the interpreter
- week 3: the writer & outputting a working file
- week 4: documentation & loose ends
It mostly worked, but I did have to stay focused to keep hitting the deadlines, and so I didn’t really have the chance to pair with other students much. (The one time I tried, I think it was just too much to grab onto; most people are much less familiar with compilers & peg.js than, say Javascript & React, which are very popular pairing topics on the floor.)
I am also looking forward to getting some deeper code review from the facilitators.
Residents
I did end up really lucking out with the residents, though, and got great advice and help from Chris Granger, who is currently working on Eve, and Pat Dubroy, who is working on Ohm, a PEG generator with a lot of great features. (I may end up rewriting the Data Monster grammar with Ohm, in fact.)
Chris suggested decoupling the data structure interpreted by Data Monster from the one generated by the semantic actions in the parser. This makes it a little easier to reason about and implement, but — even better — it means that people who hate my interface can write their own, but still use Data Monster. (In a magical future where it is much in demand.)
Chris also reminded me to be okay throwing things away. If you write code, you can always throw it out and rewrite it better — and that doesn’t mean the first time has failed. In fact, you’ve always learned something, even if the code itself did not persist. It is great advice and made it a lot easier to just make some kind of decision, even if I wasn’t certain it was definitely the best. I wonder, too, if sometimes we refactor rather than rewrite in a sort of sunk-cost-fallacy fugue.
Pat was just really great to chat with, and served as an exceptional rubber duck while I discovered ridiculous errors in my grammar. I am also dying for some of the visualization features that will ship with Ohm, including the ability to scan visually through the parser attempting to match an expression: parser errors were definitely the most challenging errors to debug in this process; often the only solution was to step through each rule mentally.
Ohm also separates matching rules from semantic actions, putting them in separate files, as opposed to the inline approach peg.js takes. It definitely seems like it will be cleaner, but only time will tell.
Overall, having Chris & Pat around really set me up for success and I am so glad the timing worked out.
Basic Schematic
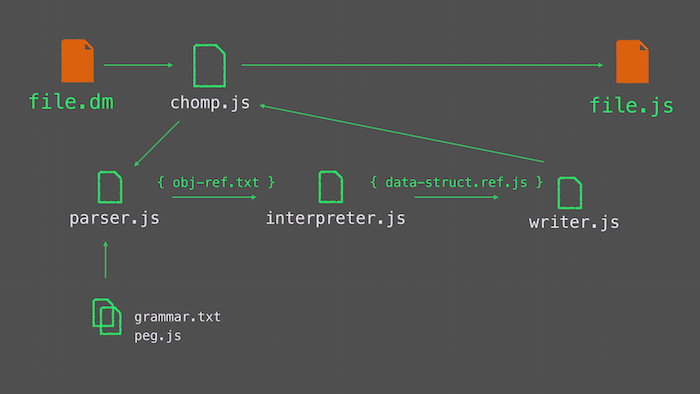
I intend to more fully map the system in the next few weeks in order to uncover some sloppy patterns, but I started by making a simple flow-chart of the files themselves for the contributing document.
(I wish more developers made these sorts of charts for their packages. I am not sure if it is just being self-taught, but I always wonder if my intuition for organization is in the mainstream.)
The chomp.js file does all the file-system and high-level compilation work. Meanwhile, the next level of files generates and interprets a set of data structures.
With the help of the grammar definition and a peg.js–generated parser, parse.js creates a structure of nested objects, each with two properties, the operator and the expression. This structure is based on my previous work with the LISP-interpreter I made and I am not sure if it makes the most sense for the target output, since it is not just about a function and a list of arguments the way most LISPs are, but it does match the input style and it is easy to reason about.
This object is then passed to interpreter.js, which transforms it into the object the writer expects. Here I do a fair amount of input processing, especially of functions.
The biggest difficulty I ran into in this step was how to return a function from a string to a recognized function. I couldn’t eval() the functions themselves because I needed to be able to write out the string into the generated file and there was no guarantee variables would be defined in the writer scope. So instead I went with:
var val = 'var moo = ' + func;
eval(val);
return moo;
While I could have destructured the arguments — either via input syntax or within the interpreter — and then used the Function object to create a new function, this solution was simpler and I enjoy the silliness of it.
Once the interpreter has done its work, writer.js takes over, concatenating strings within strings and generating the output. This remains the weakest section so far, without enough generic cases.
Things I Have Learned
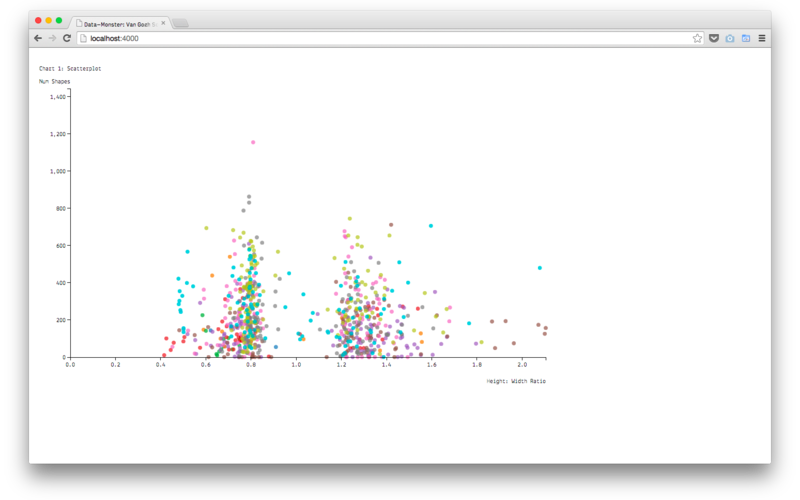
This flaw is mostly the outcome of my general approach — I took an example of my output, the code that generates this scatterplot:
sketched my desired input:
(data: 'van_gogh_additional_measurements.tsv'
(clean: #{ d.Shape_Count = +d.Shape_Count,
d.ratio = +d["Image_Height/Image_Width "]
}
)
(canvas: 1000 600 {20 20 60 60} '#scatterplot'
(color: category10)
(scale-x: linear
domain: { 0 maxX }
range: { 0 width } )
(elem: circle: { cx: d.ratio, cy: d.Shape_Count, r: 4, fill: d.Year }
attr: { 'class': 'dot' }
tooltips: true
click: #{ function(d) { window.open('https://www.google.com/search?site=imghp&tbm=isch&q=van+gogh+'+d.Title); }})
(axis-x: attr: { 'class': 'label', 'x': width, 'y': 50 }
style: { 'text-anchor': 'end' }
text: 'Height: Width Ratio' )
(axis-y: attr: { 'class': 'label', 'y': -10 }
style: { 'text-anchor': 'end' }
text: 'Num Shapes' )
)
)
and then went on to write all the code that goes in between. Sometimes by focusing on moving through each step of this generation I lost sight of the more abstract, general cases, and now as I write up the documentation, I see where I have dropped the ball. This is fixable, but if I were to write it over, I would start with the generic case.
I also learned a ton about the file system and NPM, which I did not expect but really enjoyed. I could do an entire post about the wonders of the package.json and someday I just might.
The Monster Future
But there is a lot in the Data Monster future. I will be spending the next few days filling holes I’ve identified, and then some big categories loom:
- Mapping the system.
I know there are some inefficient corners and redundancies, and by mapping out what I am doing, even to a function level, should be a really helpful way to analyze and find them. Sometimes I hate that text editors are just a big text scroll that can be hard to visualize, so I will make the map myself. - Reading books.
There are a handful of compiler and language design books out there, and they probably have useful things to say! I am glad I just jumped in on the Monster, but now that I have, some context would be good. - Adding in real error handling.
I’ve grown beyond my newb web-dev approach of “just log errors to the console” and there is a whole bunch of testing for something’s existence & then executing instead of usingtry/catch— which even I can tell is suboptimal. So, it’s time to buckle down, figure out the best approaches to errors and bubbling them up. Which is cool because it isn’t something I have thought a lot about yet, so new brain food!
Finally, a friend recently got me thinking about a fun descendant project: a DSL generator. If I can abstract out the way I built this for d3 transpiling, would it be possible to create a framework for other DSL authors?
The Web Future
In the meantime, I have a few more weeks left at Hacker School (ok, now Recurse Center, but I am … adjusting … still), and I’m planning on splitting that time between Monster updates and some web work — making a simple little site with a number of frameworks — React, Angular, maybe Ember — just as a reason to compare approaches and have something to talk about at job interviews other than parsers.
And maybe some more blog posts, too.